
Vous avez assisté à une démo où quelqu’un a lâché « pipeline RAG » comme si de rien n’était, hoché la tête quand un prestataire a mentionné « base de connaissances », et discrètement googlé « c’est quoi un LLM » sous la table. Aucune honte : le monde de l’IA va vite, et le vocabulaire encore plus vite.
Cet article est votre antisèche. Quinze termes, zéro terrier de jargon. Je vous explique chacun comme je l’expliquerais à un ami autour d’un café.
Partie 1 : Les Fondamentaux
Ces deux concepts reviennent dans presque toute conversation sur l’IA. Maîtrisez-les et le reste s’enchaîne beaucoup plus facilement.
1. LLM - Le moteur derrière les outils IA modernes
LLM signifie Large Language Model (grand modèle de langage). C’est un type d’IA entraîné sur d’énormes quantités de texte pour comprendre et générer du langage humain. Au fond, il fait une seule chose : prédire le prochain token (les petits morceaux de texte qu’on verra au #2). Donnez-lui « tout ce qui brille » et il prédit « n’est pas d’or ». Cette idée simple, mise à l’échelle sur des milliards d’exemples, produit quelque chose qui ressemble à de la compréhension.
Vous connaissez probablement les produits construits sur des LLMs : ChatGPT, Claude, Gemini. Ce sont des assistants IA, chacun adossé à des familles de modèles de leurs fournisseurs respectifs (OpenAI, Anthropic, Google, Meta, et d’autres). Sous le capot, chaque fournisseur propose plusieurs modèles optimisés pour différents compromis entre vitesse, coût et capacité.
Une note sur les coûts : Les modèles plus puissants coûtent plus cher à l’utilisation. Pour des tâches simples comme résumer des emails ou répondre à une FAQ, des modèles plus petits et moins chers (comme Claude Haiku ou Gemini Flash) fonctionnent très bien et peuvent coûter une fraction de centime par requête. Réservez les gros calibres pour le travail complexe.
Quand quelqu’un dit « on construit par-dessus un LLM », il veut dire qu’il utilise un de ces modèles comme moteur derrière son produit.
2. Token - L’unité que l’IA lit, et qui vous est facturée
Les modèles IA ne lisent pas des mots entiers. Ils découpent le texte en morceaux de sous-mots appelés tokens. Chaque modèle a son propre tokenizer, donc le découpage exact varie, mais voici grossièrement comment ça marche :
“L’intelligence artificielle transforme les entreprises” →
[L'] [intelligence] [ artificielle] [ transform] [e] [ les] [ entreprises]
En anglais, un token représente en moyenne environ trois quarts d’un mot, mais cela varie selon les langues et les modèles. Les tokens sont un détail d’implémentation, pas une unité linguistique, mais ils comptent pour deux raisons pratiques : les fournisseurs d’IA facturent au token, et chaque modèle a un nombre maximum de tokens qu’il peut traiter en une fois (on en reparle dans un instant).
Partie 2 : Travailler avec l’IA
Voici les concepts que vous rencontrerez chaque fois que vous interagissez avec ou déployez un système IA.
3. Prompt Engineering - L’art de poser la bonne question à l’IA
Chaque fois que vous tapez quelque chose dans ChatGPT, c’est un prompt. Mais un prompt bien conçu inclut du contexte, des exemples et des instructions précises. C’est la différence entre dire à un nouveau collaborateur « gère ça » et lui donner un brief détaillé avec des exemples de ce qu’on attend.
En pratique, le prompt engineering consiste généralement à construire des templates de prompts réutilisables avec des instructions structurées, des contraintes et des formats de sortie, pas juste des formulations astucieuses ponctuelles. Une technique puissante est le few-shot prompting, où vous donnez des exemples à l’IA avant de poser votre question :
Classifie ces tickets support :
"Ma commande n'est pas arrivée" → Livraison
"L'appli plante sans arrêt" → Technique
Maintenant classifie : "J'ai été facturé deux fois" → ?En voyant le pattern, l’IA donne des résultats bien plus cohérents.
4. Fenêtre de Contexte - Ce que l’IA peut voir en une fois
Chaque modèle IA a un budget fixe de tokens appelé la fenêtre de contexte. Votre saisie, les documents de référence et la réponse du modèle partagent tous ce budget.
Voyez ça comme la taille du bureau de l’IA : plus le bureau est grand, plus elle peut étaler et consulter de documents en même temps.
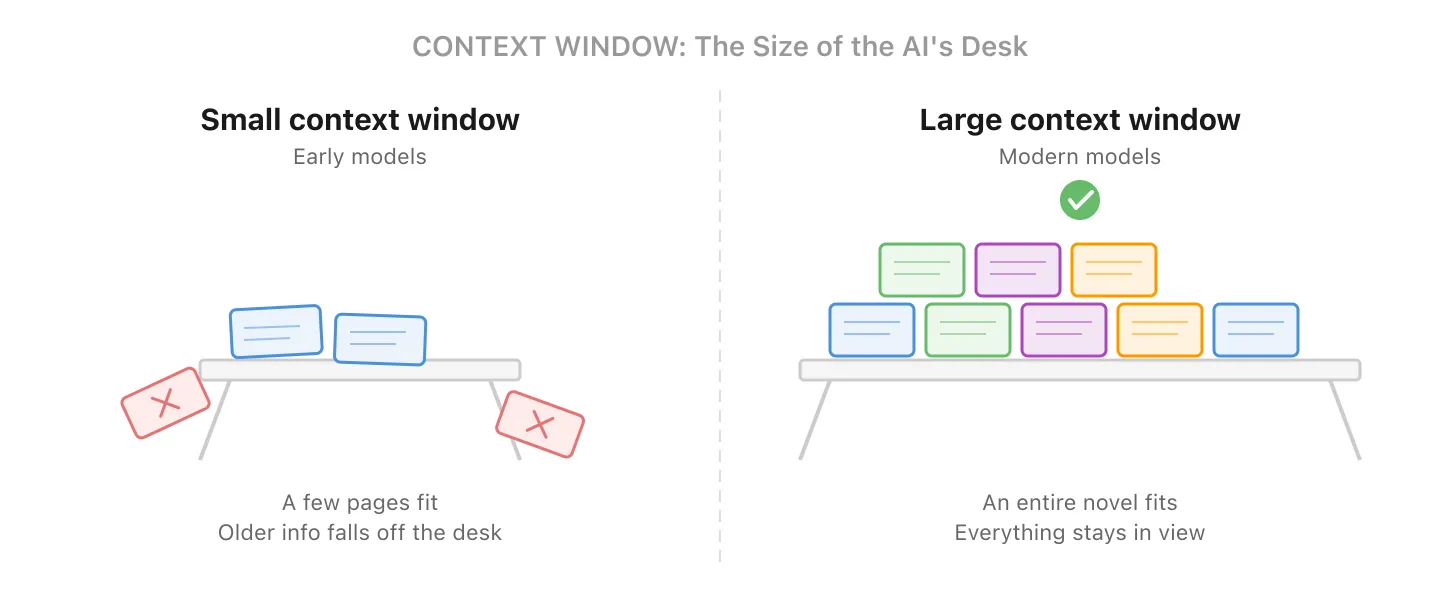
Les premiers modèles (vers 2022-2023) plafonnaient autour de 4 000-8 000 tokens, soit quelques pages de texte. Certains modèles modernes gèrent 128 000 à plus d’1 million de tokens (assez pour des centaines de pages), bien que les plus grandes fenêtres soient souvent réservées aux forfaits supérieurs ou à la tarification API. Mais il y a toujours une limite. Le modèle lui-même ne voit que ce qui tient dans la fenêtre ; quand une conversation devient trop longue, l’application en amont peut résumer, tronquer ou récupérer sélectivement les informations plus anciennes pour rester dans le budget.
Pourquoi c’est important pour les coûts : Dans une conversation par chat, chaque message que vous envoyez inclut l’historique complet de la conversation. L’IA ne lit pas juste votre dernier message ; elle relit tout depuis le début. Le coût par message augmente donc au fil de la conversation. Un fil de 50 messages coûte nettement plus par réponse qu’une conversation fraîche. C’est pourquoi beaucoup d’applications résument ou tronquent automatiquement les anciens messages en coulisses.
5. Fine-Tuning - Apprendre à l’IA un style ou comportement spécifique
Les LLMs commencent comme des généralistes : ils savent un peu de tout. Le fine-tuning les entraîne davantage sur vos données pour qu’ils adoptent un ton, format ou comportement spécifique. C’est moins pour ajouter de nouvelles connaissances factuelles (le RAG est mieux pour ça, voir #10) et plus pour façonner comment le modèle répond.
Par exemple, vous pourriez fine-tuner un modèle pour qu’il utilise toujours la voix de votre marque, suive un format de sortie spécifique ou gère de manière cohérente la terminologie de votre domaine. Les approches modernes comme LoRA (Low-Rank Adaptation) rendent cela plus rapide et moins cher que de réentraîner un modèle complet, mais ça nécessite toujours une préparation soigneuse des données et une évaluation.
En pratique : Pour la plupart des cas d’usage métier, le RAG est un point de départ plus simple et plus rentable. Le fine-tuning est idéal quand vous avez besoin d’un comportement cohérent difficile à obtenir par le prompting seul.
6. Hallucination - Quand l’IA invente avec assurance
Les LLMs génèrent du texte basé sur des patterns, pas sur des faits. Parfois ils produisent quelque chose qui semble parfaitement raisonnable mais qui est complètement faux : une fausse statistique, une affaire juridique inexistante, une citation inventée. Pensez à ce collègue qui a toujours une réponse, même quand il n’en a aucune idée. Même énergie.
C’est sans doute le terme le plus important de cette liste pour quiconque déploie de l’IA. Les hallucinations sont un risque inhérent au fonctionnement de ces modèles. Elles peuvent être considérablement réduites par l’ancrage, la récupération (RAG) et des couches de vérification, mais pas totalement éliminées. Si vous mettez de l’IA face à vos clients, vous avez besoin de garde-fous. Nous avons écrit un article plus approfondi sur ce sujet : Comment Rendre les Résultats de l’IA Fiables.
7. Guardrails - Les garde-fous de votre IA
Les guardrails sont les règles, filtres et systèmes qui empêchent votre IA de dérailler. En pratique, cela inclut plusieurs couches :
- Masquage des données personnelles : suppression automatique des données personnelles (noms, emails, numéros de téléphone) des entrées et sorties
- Filtres de politique : bloquer les réponses sur des sujets interdits ou faire respecter des règles de conformité
- Exigences de citation : forcer l’IA à référencer des documents sources plutôt que de générer de mémoire
- Listes d’outils autorisés : restreindre les actions qu’un agent IA peut effectuer (ex. : accès base de données en lecture seule)
- Humain dans la boucle : exiger une approbation manuelle avant que l’IA ne prenne des actions à fort enjeu
Ça va de simples instructions dans le prompt à des systèmes multi-couches sophistiqués. Si vous mettez de l’IA face à vos clients, les guardrails ne sont pas optionnels.
Partie 3 : Connecter l’IA à Vos Données
C’est là que ça devient intéressant. Voici les patterns qui transforment une IA générique en quelque chose qui connaît vraiment votre entreprise.
8. Base de Connaissances - La source de vérité de votre entreprise
Une base de connaissances est la collection organisée de documents, FAQ, politiques et données que vous maintenez comme matériel de référence de votre IA. Voyez ça comme le manuel employé, la doc produit et le savoir tribal, le tout réuni dans une bibliothèque bien organisée.

Le mot clé est organisée. Une base de connaissances n’est pas la même chose que le vector store ou l’index de recherche utilisé pour y puiser (ça, c’est #9 et #10). C’est la source de vérité que vous maintenez : choisir ce qui y entre, la garder à jour et la structurer pour que l’IA trouve la bonne réponse.
Sans base de connaissances, l’IA ne peut puiser que dans son entraînement général. Avec une, elle devient experte sur votre entreprise. Quand quelqu’un dit « il faut construire une base de connaissances pour le chatbot », il parle de collecter, organiser et maintenir vos informations internes pour que l’IA puisse les consulter.
9. Embeddings et Bases de Données Vectorielles - Organiser le savoir par sens, pas par mots-clés
Quand vous ajoutez des documents à une base de connaissances, un modèle d’embedding spécialisé convertit chaque morceau de texte en un embedding : une liste de nombres qui capture son sens. Imaginez une carte où chaque contenu a un emplacement. Les idées similaires sont proches, les idées sans rapport sont éloignées.
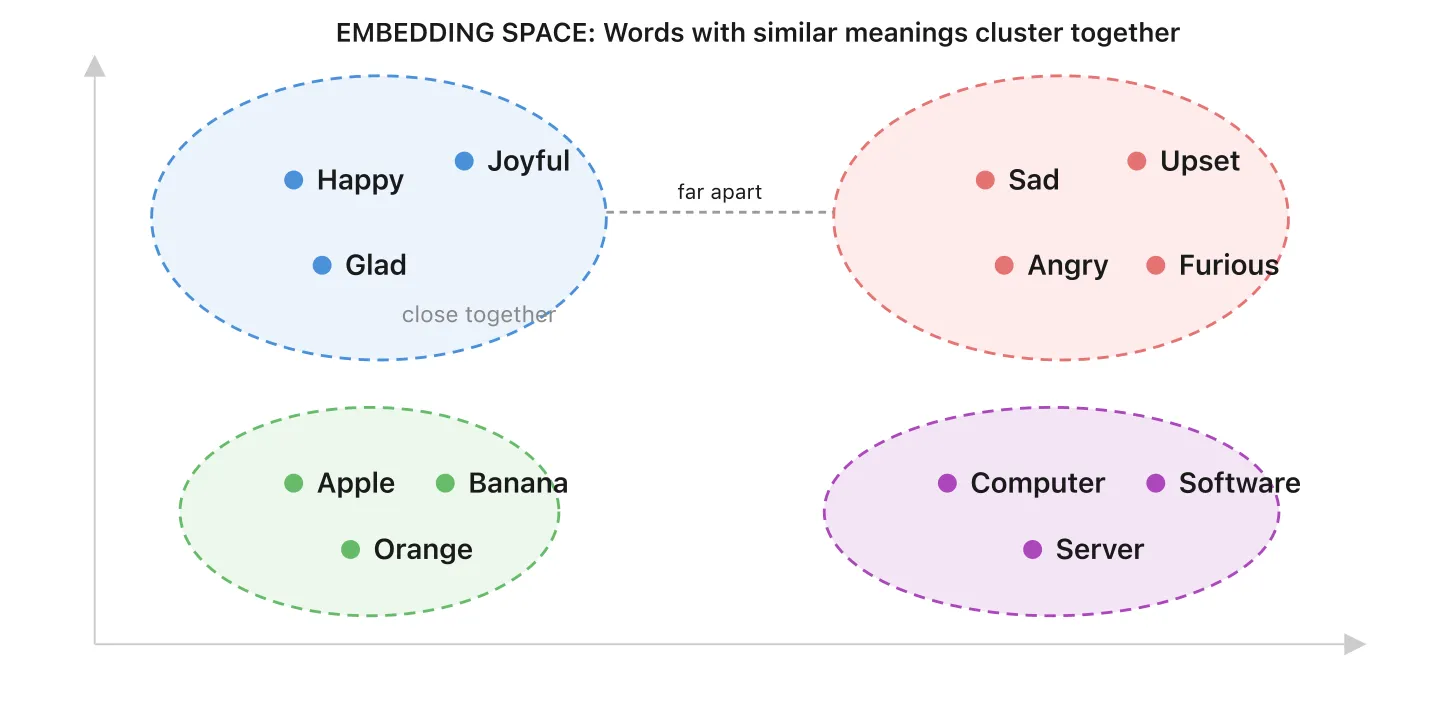
Une base de données vectorielle est l’endroit où ces embeddings sont stockés. C’est comme une bibliothèque où les livres sont rangés par sens, pas par titre. Quand un client pose une question, la base vectorielle trouve le contenu le plus pertinent par proximité sur cette carte.
Base de données traditionnelle : « Trouve-moi la ligne où catégorie = 'retours' » (correspondance exacte)
Base de données vectorielle : « Trouve-moi tout ce qui est lié aux plaintes clients sur la livraison » (correspondance de sens)
En pratique, la plupart des systèmes combinent les deux approches : recherche vectorielle pour trouver du contenu pertinent par sens, plus des filtres traditionnels (par date, catégorie ou source) pour affiner les résultats. L’une ne remplace pas l’autre.
10. RAG - Donner une antisèche à l’IA avant qu’elle ne réponde
RAG signifie Retrieval-Augmented Generation (génération augmentée par la récupération). Avant que l’IA ne réponde à votre question, elle cherche d’abord dans votre base de connaissances les informations pertinentes. Puis elle utilise ces informations pour générer une réponse fondée.
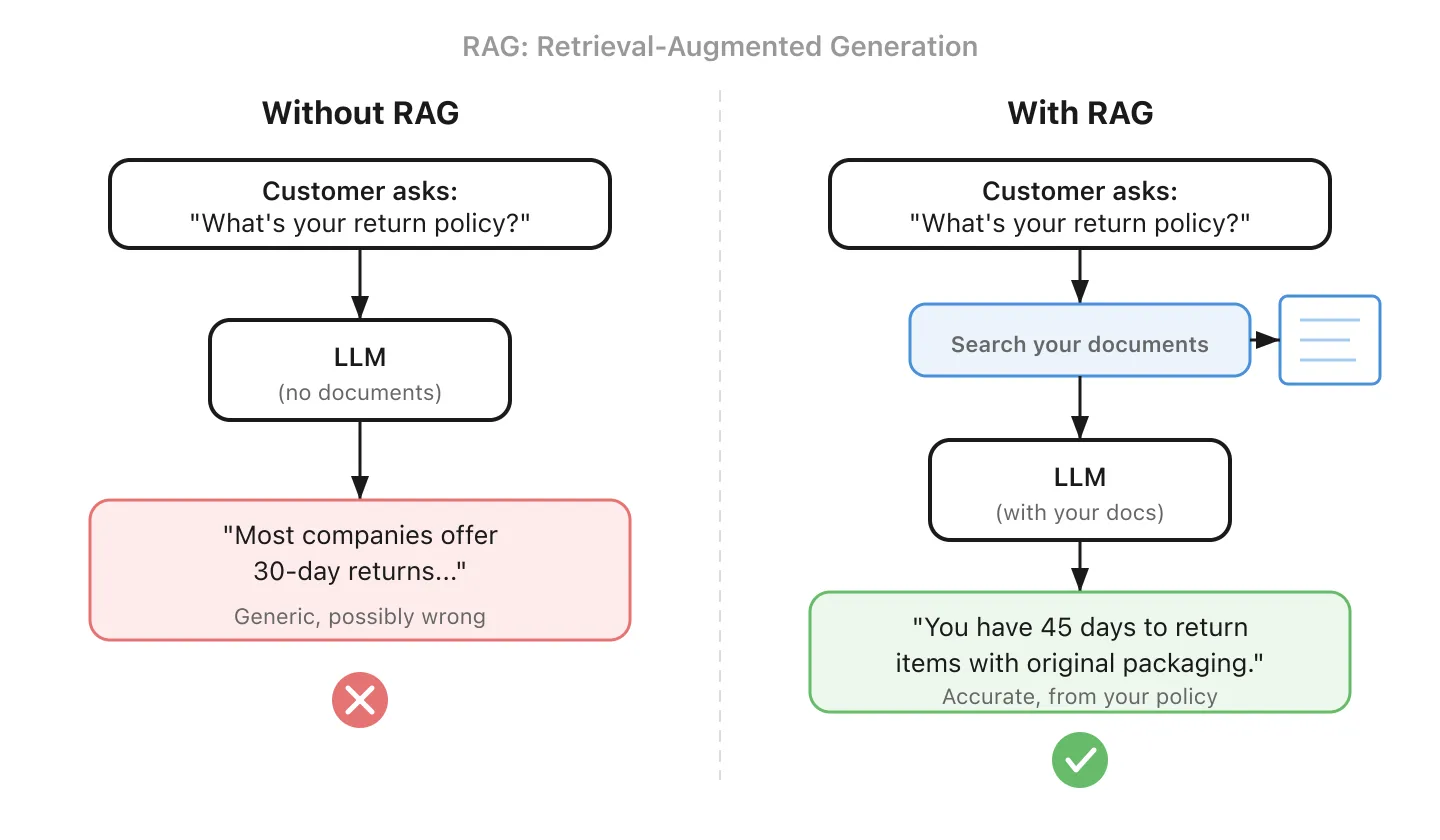
C’est la différence entre un stagiaire qui improvise et un qui consulte le guide interne d’abord. Le RAG est la façon dont la plupart des entreprises connectent l’IA à leurs propres données, et c’est généralement un point de départ plus simple que le fine-tuning (#5).
Une mise en garde importante : Le RAG n’est efficace que si la récupération l’est. Si les documents sont mal découpés, manquent de métadonnées, ou si la recherche ramène les mauvais passages, l’IA répondra avec assurance à partir de la mauvaise source. Bien paramétrer la récupération (découpage, métadonnées, re-ranking) est souvent la partie la plus difficile d’un système RAG.
11. MCP - Un standard pour connecter l’IA à vos outils
MCP signifie Model Context Protocol. C’est un standard ouvert qui définit comment les modèles IA se connectent aux outils externes et sources de données. Avant MCP, chaque intégration devait être construite sur mesure. Si vous vouliez que les données de votre CRM soient accessibles à la fois à un chatbot client et à une automatisation email interne, la logique de connexion devait être écrite deux fois, une pour chaque interface IA.
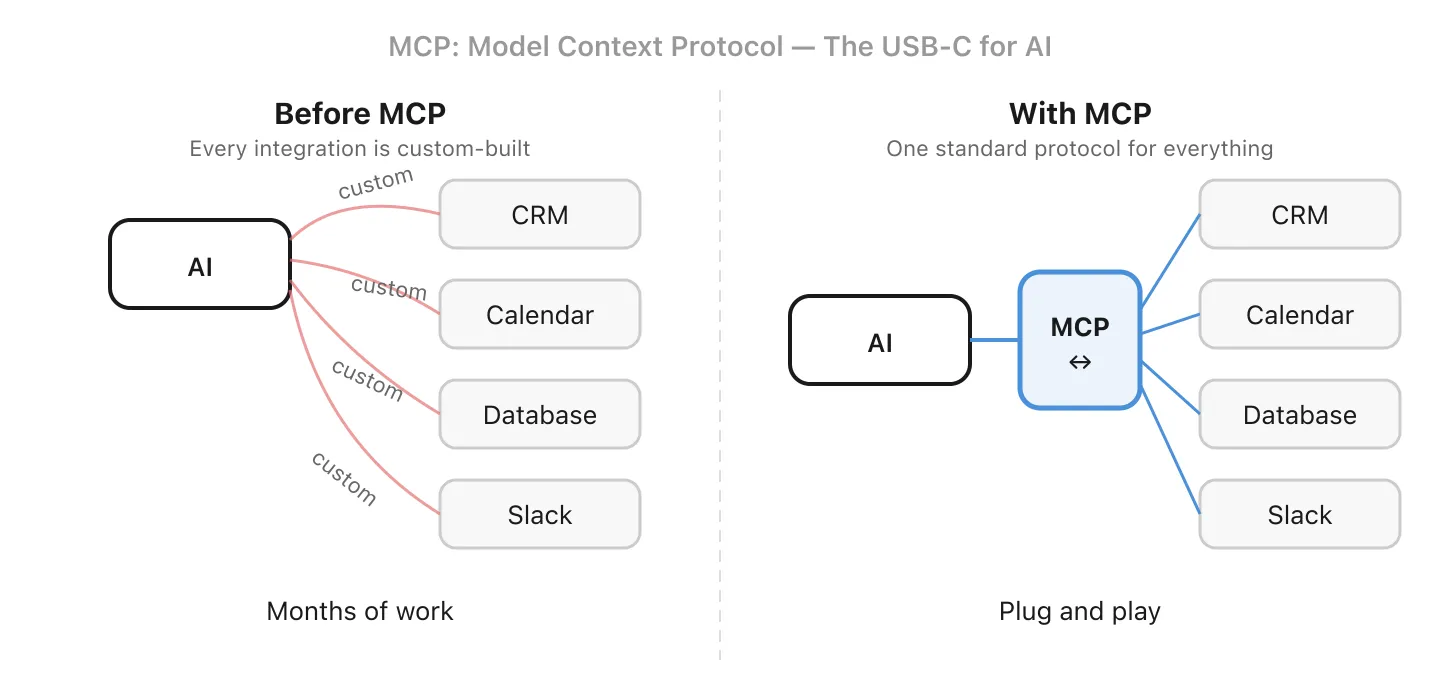
Voyez ça comme l’USB-C de l’IA : une interface commune que les outils peuvent implémenter pour que tout assistant IA compatible puisse les utiliser. Construisez un serveur MCP pour vos données métier, et n’importe quel outil compatible MCP (votre chatbot, votre assistant de code, votre agent email) peut s’y connecter sans dupliquer le travail.
Le standard est encore en maturation, et l’adoption dépend à la fois de l’outil IA et du service qui l’implémente. Des aspects clés comme l’authentification et les périmètres de permissions évoluent activement. Mais la direction est claire : des intégrations standardisées plutôt que du code sur mesure à chaque fois.
Partie 4 : La Frontière
Ces concepts façonnent la manière dont l’IA est construite et utilisée aujourd’hui.
12. Context Engineering - Concevoir ce que l’IA voit et quand
Le context engineering est un terme relativement nouveau qui décrit la pratique de conception du pipeline complet d’information autour d’un système IA. Il va au-delà du prompt engineering (#3) pour englober :
- Routage : décider quel modèle ou outil traite chaque requête
- Gestion de la mémoire : résumer ou tronquer l’historique de conversation pour rester dans le budget de tokens
- Orchestration de la récupération : aller chercher les bons documents via RAG (#10) au bon moment
- Sélection d’outils : choisir quelles intégrations (#11) invoquer
- Formatage de sortie : structurer les réponses pour les systèmes en aval
Si le prompt engineering c’est écrire un bon email, le context engineering c’est concevoir tout le workflow de communication. Le terme n’est pas encore universellement standardisé, mais la pratique devient rapidement essentielle à mesure que les systèmes IA se complexifient.
13. Agent IA - L’IA qui ne se contente pas de répondre, elle agit
Un chatbot IA classique répond aux questions. Un agent IA peut véritablement faire des choses : il décompose une tâche en étapes, décide quels outils utiliser et exécute. Vous en utilisez peut-être déjà un : Claude Code écrit et exécute du code sur des projets entiers, et le mode « operator » de ChatGPT peut naviguer sur le web et remplir des formulaires à votre place.
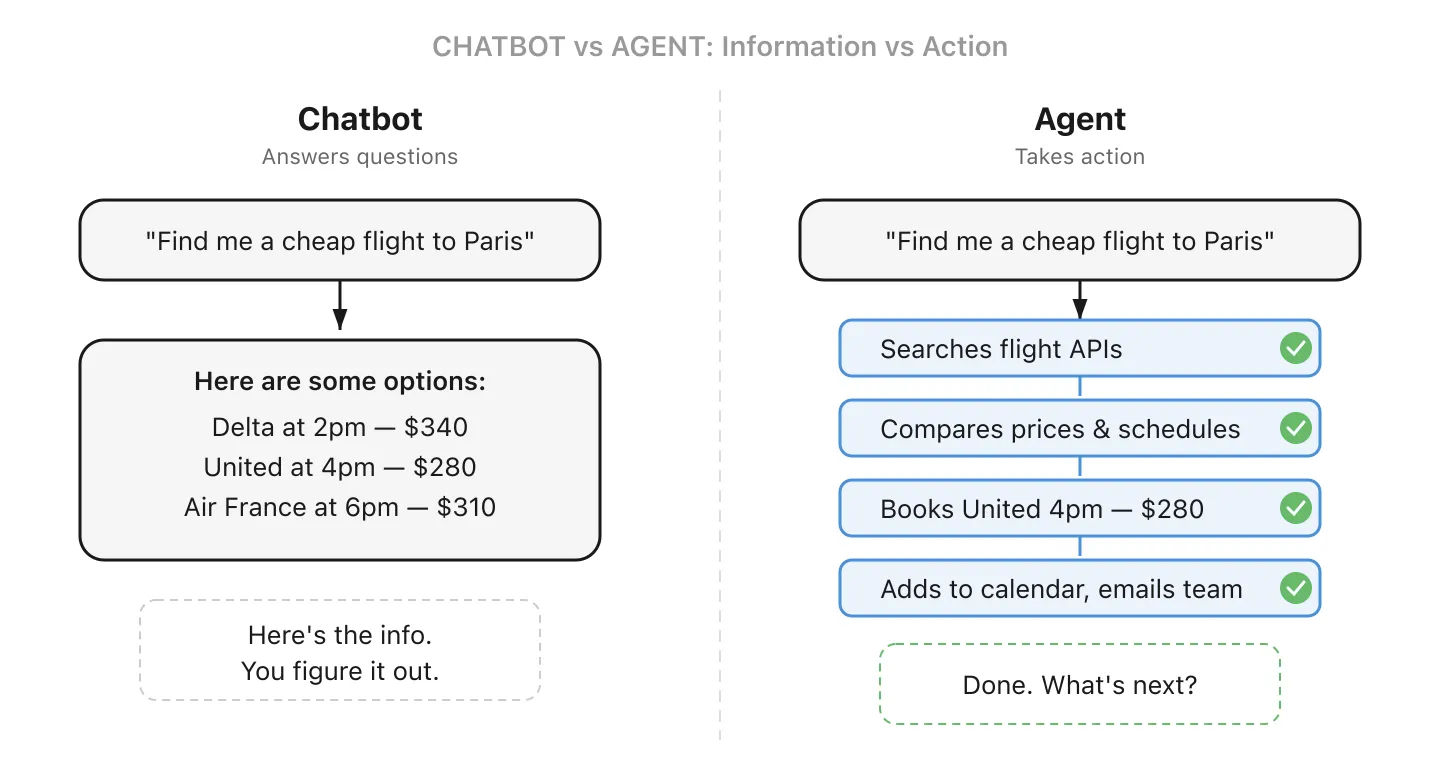
Pour une petite entreprise, un agent pourrait surveiller votre adresse « contact@ », rédiger des réponses aux questions courantes et ne vous alerter que pour les cas complexes. Ou il pourrait traiter les factures entrantes, les rapprocher des bons de commande et signaler les écarts pour vérification. La différence clé avec un chatbot : il agit en votre nom, il ne se contente pas de fournir de l’information.
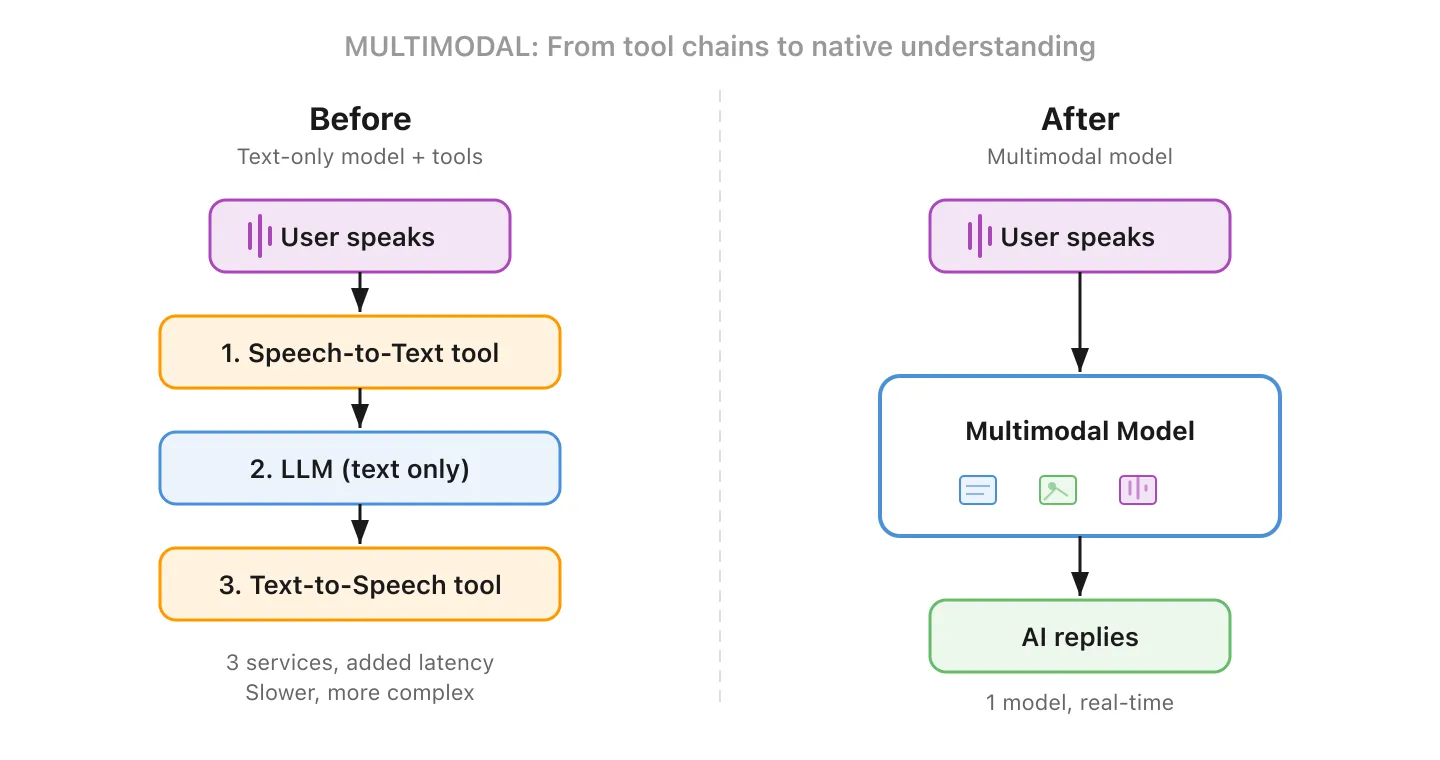
14. Multimodal - L’IA qui peut voir, entendre et lire
Les premiers LLMs ne pouvaient traiter que du texte. Les modèles multimodaux peuvent travailler avec plusieurs types d’entrées et de sorties : texte, images, audio et vidéo. Montrez-lui une photo d’un produit endommagé et demandez-lui de rédiger une réclamation. Donnez-lui un graphique et demandez-lui d’expliquer les tendances.
C’est plus important qu’il n’y paraît. Avant le multimodal, construire un assistant vocal IA nécessitait d’enchaîner des outils séparés : un service de speech-to-text pour transcrire, un LLM pour générer une réponse, et un service de text-to-speech pour la lire. Chaque étape ajoutait de la latence et du coût. Un modèle multimodal gère tout le flux nativement, ce qui rend les conversations vocales en temps réel naturelles plutôt que saccadées.
15. Modèle de Raisonnement - L’IA qui réfléchit avant de répondre
La plupart des assistants IA répondent directement. Les modèles de raisonnement dépensent du calcul supplémentaire pour travailler un problème étape par étape avant de répondre, vérifiant les hypothèses et détectant les erreurs en chemin. Certains exposent cette réflexion de manière visible (comme DeepSeek R1), tandis que d’autres (comme o3 d’OpenAI) raisonnent en interne et ne renvoient que la réponse finale.
Le compromis : du temps et du coût en échange de la précision. Les modèles de raisonnement excellent pour l’analyse financière, la revue juridique et l’interprétation de données. Pour les tâches du quotidien, les modèles standards sont plus rapides et moins chers.
En Résumé
Le vocabulaire de l’IA peut sembler être une barrière, mais la plupart de ces concepts correspondent à des idées que vous comprenez déjà. Les termes existent parce que la technologie est vraiment nouvelle, pas parce que quelqu’un cherche à vous embrouiller.
La prochaine fois qu’un prestataire vous présentera une « solution RAG agentique avec intégrations MCP et raisonnement multimodal », vous saurez exactement ce qu’il veut dire, et surtout, vous saurez quelles questions poser.
Un terme que j’ai oublié ? Ou un qui reste flou ? Contactez l’équipe Flowful, on adore aider les entreprises à comprendre l’IA.