
U hebt al eens een demo bijgewoond waarin iemand achteloos “RAG-pipeline” liet vallen, instemmend knikte toen een leverancier “kennisbank” vermeldde, en stiekem onder de tafel “wat is een LLM” googelde. Geen schaamte: de AI-wereld gaat snel, en de woordenschat gaat nog sneller.
Dit artikel is uw spiekbriefje. Vijftien termen, geen eindeloze jargontunnels. Ik leg elke term uit zoals ik die aan een vriend zou uitleggen bij een kop koffie.
Deel 1: De bouwstenen
Deze twee concepten komen in bijna elk gesprek over AI terug. Beheers ze en de rest valt veel sneller op zijn plek.
1. LLM - De motor achter moderne AI-tools
LLM staat voor Large Language Model (groot taalmodel). Het is een type AI dat getraind is op enorme hoeveelheden tekst om menselijke taal te begrijpen en te genereren. In de kern doet het één ding: de volgende token voorspellen (de kleine stukjes tekst die we bij #2 behandelen). Geef het “al wat blinkt” en het voorspelt “is geen goud”. Dat eenvoudige idee, opgeschaald naar miljarden voorbeelden, levert iets op dat aanvoelt als begrip.
U kent waarschijnlijk de producten die bovenop LLM’s zijn gebouwd: ChatGPT, Claude, Gemini. Dit zijn AI-assistenten, elk gedragen door modelfamilies van hun respectieve aanbieders (OpenAI, Anthropic, Google, Meta en anderen). Onder de motorkap biedt elke aanbieder meerdere modellen, afgestemd op verschillende afwegingen tussen snelheid, kosten en capaciteit.
Een opmerking over kosten: Krachtigere modellen kosten meer per gebruik. Voor eenvoudige taken zoals het samenvatten van e-mails of het beantwoorden van FAQ’s werken kleinere, goedkopere modellen (zoals Claude Haiku of Gemini Flash) prima en kunnen ze een fractie van een cent per aanvraag kosten. Bewaar de zware jongens voor complex werk.
Wanneer iemand zegt “we bouwen bovenop een LLM”, bedoelt hij dat hij een van deze modellen gebruikt als motor achter zijn product.
2. Token - De eenheid die AI inleest, en die u aangerekend wordt
AI-modellen lezen geen volledige woorden. Ze knippen tekst in deelwoordstukjes die tokens worden genoemd. Elk model heeft zijn eigen tokenizer, dus de exacte opsplitsing verschilt, maar zo werkt het ruwweg:
“Artificiële intelligentie transformeert bedrijven” →
[Artifici] [ële] [ intelligentie] [ transform] [eert] [ bedrijven]
In het Engels staat een token gemiddeld voor ongeveer driekwart van een woord, hoewel dit varieert per taal en model. Tokens zijn een implementatiedetail, geen taalkundige eenheid, maar ze zijn belangrijk om twee praktische redenen: AI-aanbieders rekenen per token aan, en elk model heeft een maximaal aantal tokens dat het tegelijk kan verwerken (daarover zo meteen meer).
Deel 2: Werken met AI
Dit zijn de concepten die u tegenkomt telkens wanneer u met een AI-systeem werkt of er een uitrolt.
3. Prompt engineering - De kunst om AI de juiste vraag te stellen
Telkens wanneer u iets in ChatGPT typt, is dat een prompt. Maar een goed opgestelde prompt bevat context, voorbeelden en specifieke instructies. Het is het verschil tussen een nieuwe medewerker zeggen “regel dit even” en hem een gedetailleerde briefing geven met voorbeelden van wat goed werk is.
In de praktijk betekent prompt engineering meestal het bouwen van herbruikbare prompttemplates met gestructureerde instructies, beperkingen en uitvoerformaten, niet zomaar slimme eenmalige formuleringen. Een krachtige techniek is few-shot prompting, waarbij u de AI voorbeelden geeft voordat u uw vraag stelt:
Classificeer deze supporttickets:
"Mijn bestelling is niet aangekomen" → Verzending
"De app blijft crashen" → Technisch
Classificeer nu: "Ik werd twee keer aangerekend" → ?Door het patroon te zien, geeft de AI u veel consistentere resultaten.
4. Contextvenster - Hoeveel de AI in één keer kan zien
Elk AI-model heeft een vast tokenbudget dat het contextvenster wordt genoemd. Uw invoer, eventuele achtergronddocumenten en het antwoord van het model zelf delen allemaal dit budget.
Zie het als de grootte van het bureau van de AI: hoe groter het bureau, hoe meer documenten het tegelijk kan uitspreiden en raadplegen.
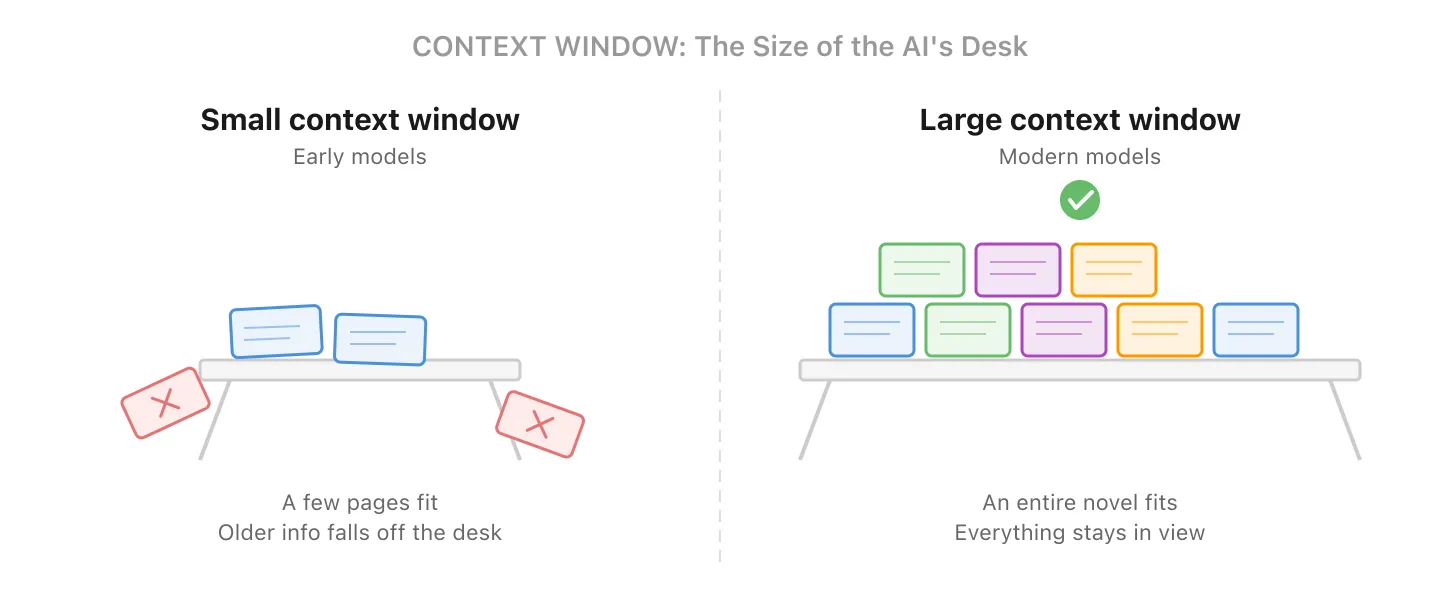
Vroege modellen (rond 2022-2023) bleven steken rond 4.000 tot 8.000 tokens, zowat enkele pagina’s tekst. Sommige moderne modellen verwerken 128.000 tot meer dan 1 miljoen tokens (genoeg voor honderden pagina’s), al komen de grootste vensters vaak met duurdere abonnementen of API-tarieven. Maar er is altijd een limiet. Het model zelf ziet enkel wat in het venster past; wanneer een gesprek te lang wordt, kan de toepassing ervoor oudere informatie samenvatten, inkorten of selectief ophalen om binnen het budget te blijven.
Waarom dit belangrijk is voor de kosten: In een chatgesprek bevat elk bericht dat u verstuurt de volledige gespreksgeschiedenis. De AI leest niet alleen uw laatste bericht; ze herleest alles vanaf het begin. De kost per bericht groeit dus naarmate het gesprek langer wordt. Een thread met 50 berichten kost per antwoord aanzienlijk meer dan een vers gesprek. Daarom vatten veel toepassingen oudere berichten automatisch samen of korten ze die achter de schermen in.
5. Fine-tuning - De AI een specifieke stijl of gedrag aanleren
LLM’s beginnen als generalisten: ze weten van alles een beetje. Fine-tuning traint ze verder op uw data zodat ze een specifieke toon, opmaak of gedrag overnemen. Het gaat minder om het toevoegen van nieuwe feiten (RAG is daar beter voor, zie #10) en meer om het vormgeven van hoe het model antwoordt.
U zou bijvoorbeeld een model kunnen fine-tunen zodat het altijd de stem van uw merk gebruikt, een specifiek uitvoerformaat volgt of de terminologie van uw vakgebied consistent hanteert. Moderne benaderingen zoals LoRA (Low-Rank Adaptation) maken dit sneller en goedkoper dan een volledig model opnieuw trainen, maar het vereist nog steeds een zorgvuldige voorbereiding en evaluatie van de data.
In de praktijk: Voor de meeste zakelijke toepassingen is RAG een eenvoudiger en kostenefficiënter startpunt. Fine-tuning komt tot zijn recht wanneer u consistent gedrag nodig hebt dat moeilijk te bereiken is met prompting alleen.
6. Hallucinatie - Wanneer AI met overtuiging dingen verzint
LLM’s genereren tekst op basis van patronen, niet van feiten. Soms produceren ze iets dat perfect redelijk klinkt maar compleet fout is: een verzonnen statistiek, een onbestaande rechtszaak, een citaat dat niet bestaat. Denk aan die ene collega die altijd een antwoord heeft, zelfs als hij geen idee heeft. Diezelfde energie.
Dit is wellicht de belangrijkste term in deze lijst voor iedereen die AI uitrolt. Hallucinaties zijn een inherent risico van de manier waarop deze modellen werken. Ze kunnen aanzienlijk worden verminderd door grounding, retrieval (RAG) en verificatielagen, maar niet volledig worden geëlimineerd. Als u AI voor uw klanten plaatst, hebt u voorzorgsmaatregelen nodig. We schreven een diepgaander artikel over dit onderwerp: Hoe u AI-resultaten betrouwbaar maakt.
7. Guardrails - Veiligheidshekken voor uw AI
Guardrails zijn de regels, filters en systemen die voorkomen dat uw AI ontspoort. In de praktijk omvat dit meerdere lagen:
- Maskeren van persoonsgegevens: automatisch persoonsgegevens (namen, e-mails, telefoonnummers) uit invoer en uitvoer verwijderen
- Beleidsfilters: antwoorden over verboden onderwerpen blokkeren of nalevingsregels afdwingen
- Bronvermeldingsvereisten: de AI dwingen om naar brondocumenten te verwijzen in plaats van uit het geheugen te genereren
- Lijsten met toegestane tools: beperken welke acties een AI-agent mag uitvoeren (bijv. alleen-lezen toegang tot de database)
- Mens in de lus: handmatige goedkeuring vereisen voordat de AI acties met hoge inzet onderneemt
Dit gaat van eenvoudige instructies in de prompt tot geavanceerde meerlaagse systemen. Als u AI voor uw klanten plaatst, zijn guardrails niet optioneel.
Deel 3: AI verbinden met uw data
Hier wordt het interessant. Dit zijn de patronen die een generieke AI omtoveren tot iets dat uw bedrijf echt kent.
8. Kennisbank - De gecureerde bron van waarheid van uw bedrijf
Een kennisbank is de georganiseerde verzameling documenten, FAQ’s, beleidsregels en data die u onderhoudt als referentiemateriaal voor uw AI. Zie het als het personeelshandboek, de productdocumentatie en de stilzwijgende bedrijfskennis, allemaal samengebracht in één gecureerde bibliotheek.

Het sleutelwoord is gecureerd. Een kennisbank is niet hetzelfde als de vector store of zoekindex die gebruikt wordt om eruit te halen (dat zijn #9 en #10). Het is de bron van waarheid die u onderhoudt: kiezen wat erin komt, ze actueel houden en ze zo structureren dat de AI het juiste antwoord vindt.
Zonder kennisbank kan AI alleen putten uit haar algemene training. Mét een kennisbank wordt ze een expert over uw bedrijf. Wanneer iemand zegt “we moeten een kennisbank bouwen voor de chatbot”, bedoelt hij het verzamelen, organiseren en onderhouden van uw interne informatie zodat de AI die kan raadplegen.
9. Embeddings en vectordatabases - Kennis ordenen op betekenis, niet op trefwoorden
Wanneer u documenten toevoegt aan een kennisbank, zet een gespecialiseerd embeddingmodel elk stukje tekst om in een embedding: een reeks getallen die de betekenis ervan vastlegt. Stel u een kaart voor waarop elk stuk content een plek heeft. Gelijkaardige ideeën liggen dicht bij elkaar, niet-verwante ideeën liggen ver uit elkaar.
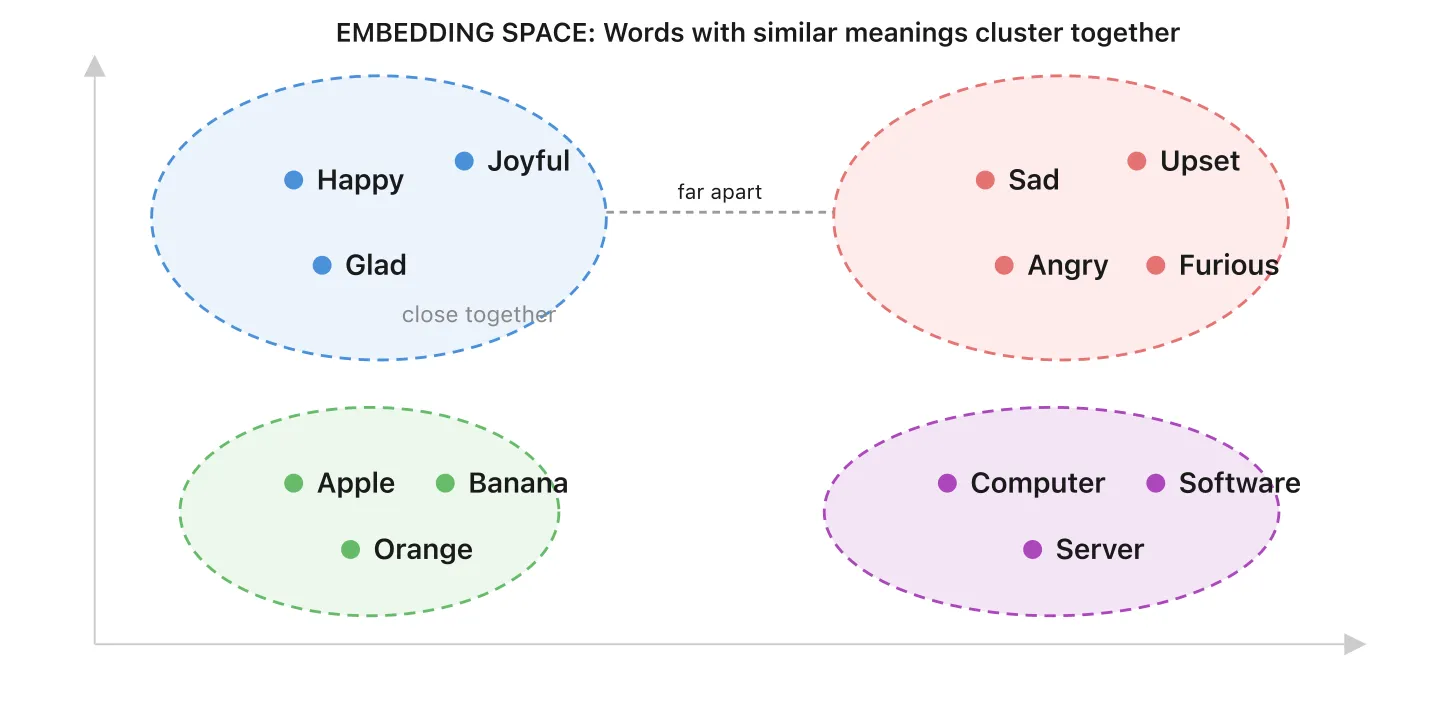
Een vectordatabase is de plek waar deze embeddings worden bewaard. Het is als een bibliotheek waar boeken op betekenis zijn geordend, niet op titel. Wanneer een klant een vraag stelt, vindt de vectordatabase de meest relevante content op basis van nabijheid op die kaart.
Traditionele database: “Zoek de rij waar categorie = 'retours'” (exacte overeenkomst)
Vectordatabase: “Zoek alles wat verband houdt met klachten van klanten over verzending” (overeenkomst op betekenis)
In de praktijk combineren de meeste systemen beide benaderingen: vectorzoeken om relevante content op betekenis te vinden, plus traditionele filters (op datum, categorie of bron) om de resultaten te verfijnen. De ene vervangt de andere niet.
10. RAG - De AI een spiekbriefje geven voordat ze antwoordt
RAG staat voor Retrieval-Augmented Generation (generatie aangevuld met retrieval). Voordat de AI uw vraag beantwoordt, doorzoekt ze eerst uw kennisbank om relevante informatie te vinden. Vervolgens gebruikt ze die informatie om een gefundeerd antwoord te genereren.
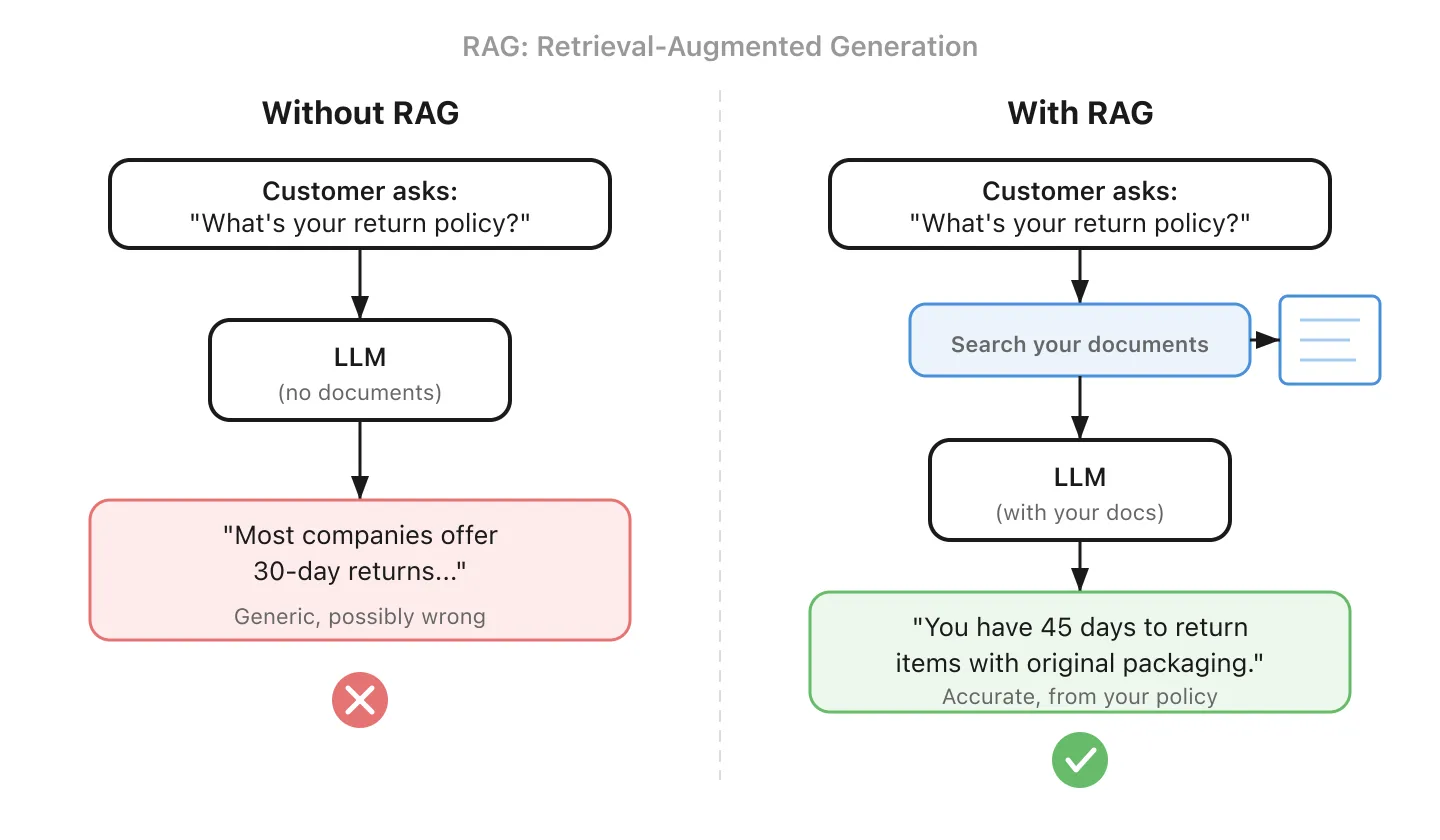
Het is het verschil tussen een stagiair die improviseert en een die eerst het handboek raadpleegt. RAG is de manier waarop de meeste bedrijven AI met hun eigen data verbinden, en het is meestal een eenvoudiger startpunt dan fine-tuning (#5).
Een belangrijke kanttekening: RAG is maar zo goed als zijn retrieval. Als documenten slecht zijn opgedeeld, metadata missen, of als de zoekopdracht de verkeerde passages teruggeeft, zal de AI met overtuiging antwoorden uit de verkeerde bron. De retrieval goed krijgen (opdeelstrategie, metadata, re-ranking) is vaak het moeilijkste deel van het bouwen van een RAG-systeem.
11. MCP - Een standaardmanier om AI met uw tools te verbinden
MCP staat voor Model Context Protocol. Het is een open standaard die definieert hoe AI-modellen verbinding maken met externe tools en gegevensbronnen. Vóór MCP moest elke integratie op maat worden gebouwd. Als u wilde dat uw CRM-data beschikbaar was voor zowel een klantchatbot als een interne e-mailautomatisering, moest de verbindingslogica twee keer worden geschreven, één keer voor elke AI-interface.
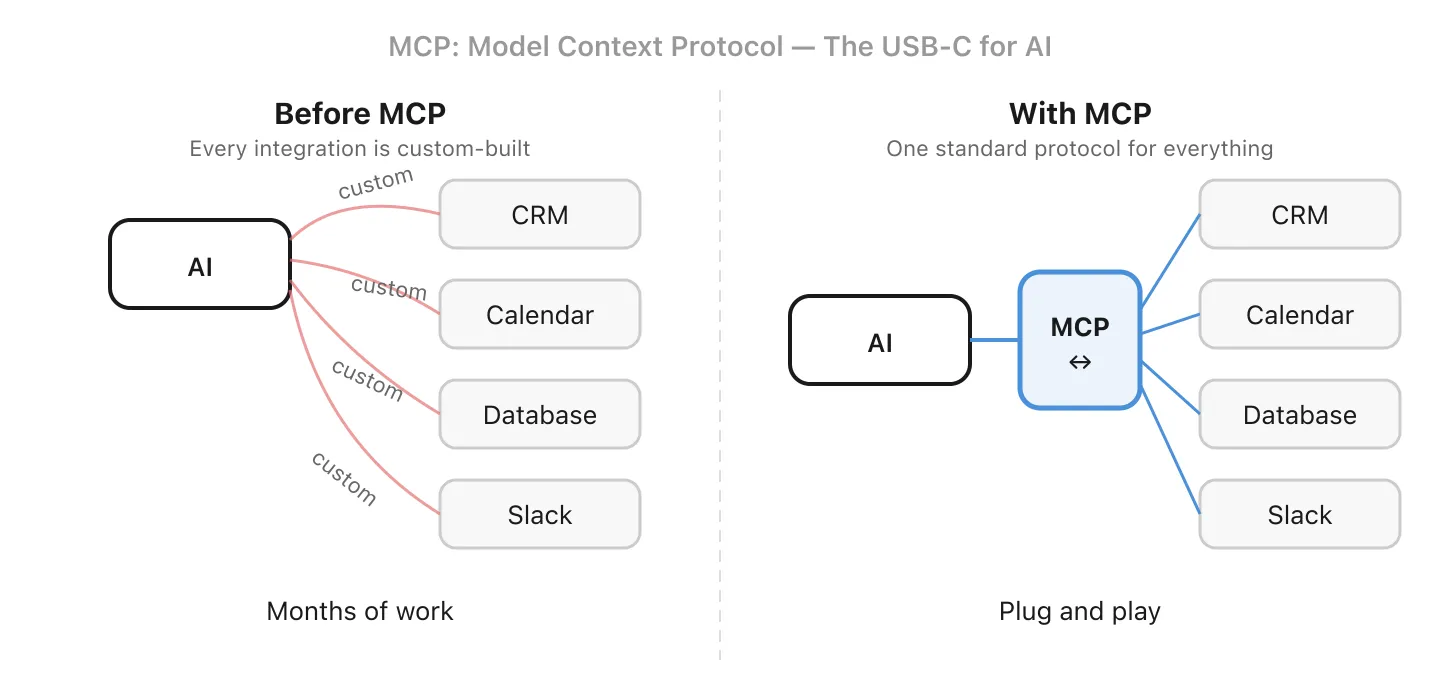
Zie het als de USB-C voor AI: een gemeenschappelijke interface die tools kunnen implementeren zodat elke compatibele AI-assistent ze kan gebruiken. Bouw één MCP-server voor uw bedrijfsdata, en elke MCP-compatibele tool (uw chatbot, uw codeerassistent, uw e-mailagent) kan ermee verbinden zonder dubbel werk.
De standaard is nog volop in ontwikkeling, en de adoptie hangt af van zowel de AI-tool als de dienst die hem implementeert. Belangrijke aspecten zoals authenticatie en permissieperimeters evolueren actief. Maar de richting is duidelijk: gestandaardiseerde integraties in plaats van telkens code op maat.
Deel 4: De frontlinie
Deze concepten bepalen hoe AI vandaag wordt gebouwd en gebruikt.
12. Context engineering - Ontwerpen wat de AI ziet en wanneer
Context engineering is een relatief nieuwe term die de praktijk beschrijft van het ontwerpen van de volledige informatiepijplijn rond een AI-systeem. Het gaat verder dan prompt engineering (#3) en omvat:
- Routering: beslissen welk model of welke tool elke aanvraag afhandelt
- Geheugenbeheer: de gespreksgeschiedenis samenvatten of inkorten om binnen het tokenbudget te blijven
- Orkestratie van retrieval: de juiste documenten ophalen via RAG (#10) op het juiste moment
- Toolselectie: kiezen welke integraties (#11) worden aangeroepen
- Uitvoeropmaak: antwoorden structureren voor systemen verderop in de keten
Als prompt engineering het schrijven van een goede e-mail is, dan is context engineering het ontwerpen van de volledige communicatieworkflow. De term is nog niet universeel gestandaardiseerd, maar de praktijk wordt snel essentieel naarmate AI-systemen complexer worden.
13. AI-agent - AI die niet alleen antwoordt, maar handelt
Een gewone AI-chatbot beantwoordt vragen. Een AI-agent kan echt dingen doen: hij splitst een taak op in stappen, beslist welke tools hij gebruikt en voert uit. U gebruikt er misschien al een: Claude Code schrijft en draait code over volledige projecten, en de “operator”-modus van ChatGPT kan op het web surfen en formulieren voor u invullen.
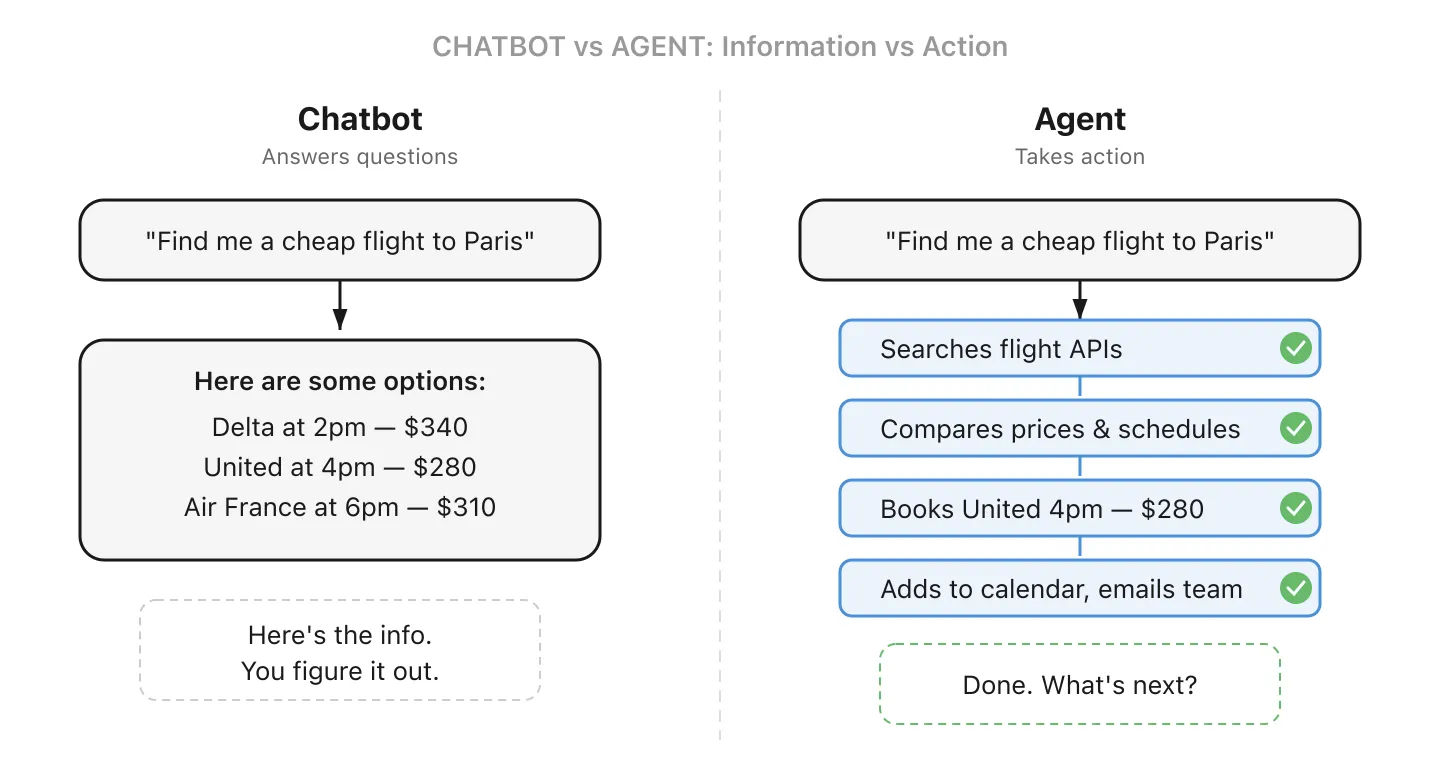
Voor een kleine onderneming zou een agent uw “info@“-adres kunnen bewaken, antwoorden op veelgestelde vragen kunnen opstellen en u alleen waarschuwen bij de complexe gevallen. Of hij zou inkomende facturen kunnen verwerken, ze afstemmen op bestelbonnen en afwijkingen markeren ter controle. Het cruciale verschil met een chatbot: hij onderneemt actie in uw naam, hij geeft niet alleen informatie.
14. Multimodaal - AI die kan zien, horen en lezen
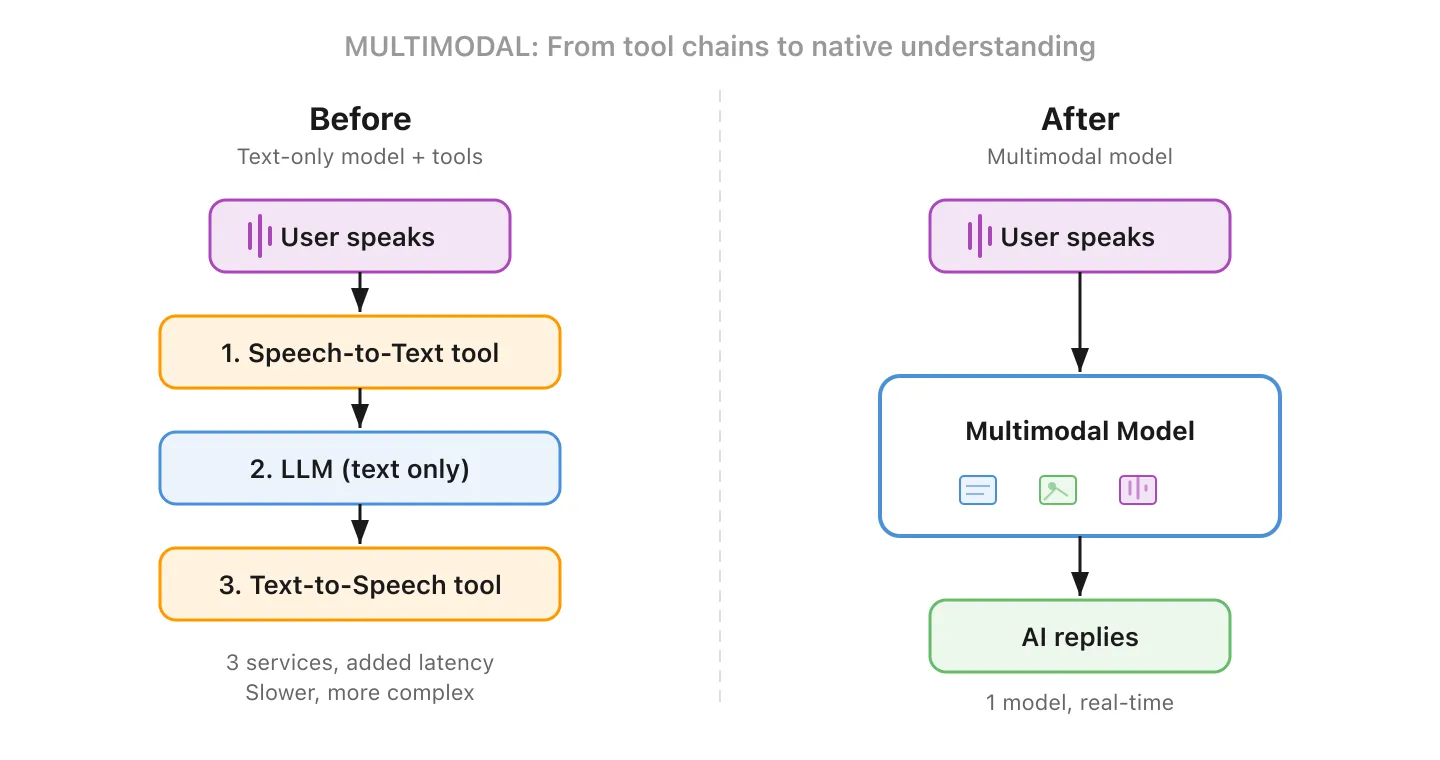
De meeste vroege LLM’s konden alleen tekst verwerken. Multimodale modellen kunnen werken met meerdere types invoer en uitvoer: tekst, beelden, audio en video. Toon het een foto van een beschadigd product en vraag het een klacht op te stellen. Geef het een grafiek en vraag het de trends uit te leggen.
Dit is een grotere zaak dan het klinkt. Vóór multimodaal betekende het bouwen van een spraakgestuurde AI-assistent dat u afzonderlijke tools aan elkaar moest knopen: een speech-to-textdienst om te transcriberen, een LLM om een antwoord te genereren, en een text-to-speechdienst om het voor te lezen. Elke stap voegde latency en kosten toe. Een multimodaal model handelt de volledige stroom native af, waardoor realtime spraakgesprekken natuurlijk aanvoelen in plaats van houterig.
15. Redeneermodel - AI die nadenkt voordat ze antwoordt
De meeste AI-assistenten antwoorden meteen. Redeneermodellen besteden extra rekenkracht aan het stap voor stap doorwerken van een probleem voordat ze antwoorden, waarbij ze aannames controleren en onderweg fouten opvangen. Sommige tonen dit denkproces zichtbaar (zoals DeepSeek R1), terwijl andere (zoals o3 van OpenAI) intern redeneren en enkel het eindantwoord teruggeven.
De afweging: tijd en kosten in ruil voor nauwkeurigheid. Redeneermodellen blinken uit bij financiële analyse, juridische beoordeling en data-interpretatie. Voor dagelijkse taken zijn standaardmodellen sneller en goedkoper.
Tot slot
De woordenschat van AI kan als een barrière aanvoelen, maar de meeste van deze concepten sluiten aan bij ideeën die u al begrijpt. De termen bestaan omdat de technologie echt nieuw is, niet omdat iemand u in de war wil brengen.
De volgende keer dat een leverancier u een “agentische RAG-oplossing met MCP-integraties en multimodaal redeneren” voorstelt, weet u precies wat hij bedoelt, en belangrijker nog, weet u welke vragen u moet stellen.
Een term die ik vergeten ben? Of een die nog steeds onduidelijk blijft? Neem contact op met het Flowful-team, we helpen bedrijven maar al te graag om AI te begrijpen.